개요
https://bean-conding.tistory.com/22
시작하기에 앞서...
나는 학부시절 와글와글이라는 웹사이트를 만든적 있다. 이때 당시 코로나로 인해서 선후배간의 연결성이 떨어지는 문제점이 있었고, 이를 해소하고자 선후배를 매칭 시켜 채팅을 할 수 있게끔
bean-conding.tistory.com
윗글을 보시면 게시판 프로젝트를 통해 대용량 처리를 위한 성능 부분을 공부한다고 했었다.
시간이 꽤 지났지만... 꾸준히 커밋을 하며 기본틀인 게시판 프로젝트를 만들었고, 이제 Redis를 이용해서 캐싱을 적용해보고 성능 테스트를 해볼려고한다.
뼈대 프로젝트는 아래의 깃허브를 들어가보면 코드를 볼수 있다.
https://github.com/wjddudqls96/bigTrafficBoardService
GitHub - wjddudqls96/bigTrafficBoardService: 대용량 트래픽 와 데이터 처리가 가능한 게시판을 목표로 만드
대용량 트래픽 와 데이터 처리가 가능한 게시판을 목표로 만드는 프로젝트입니다. Contribute to wjddudqls96/bigTrafficBoardService development by creating an account on GitHub.
github.com
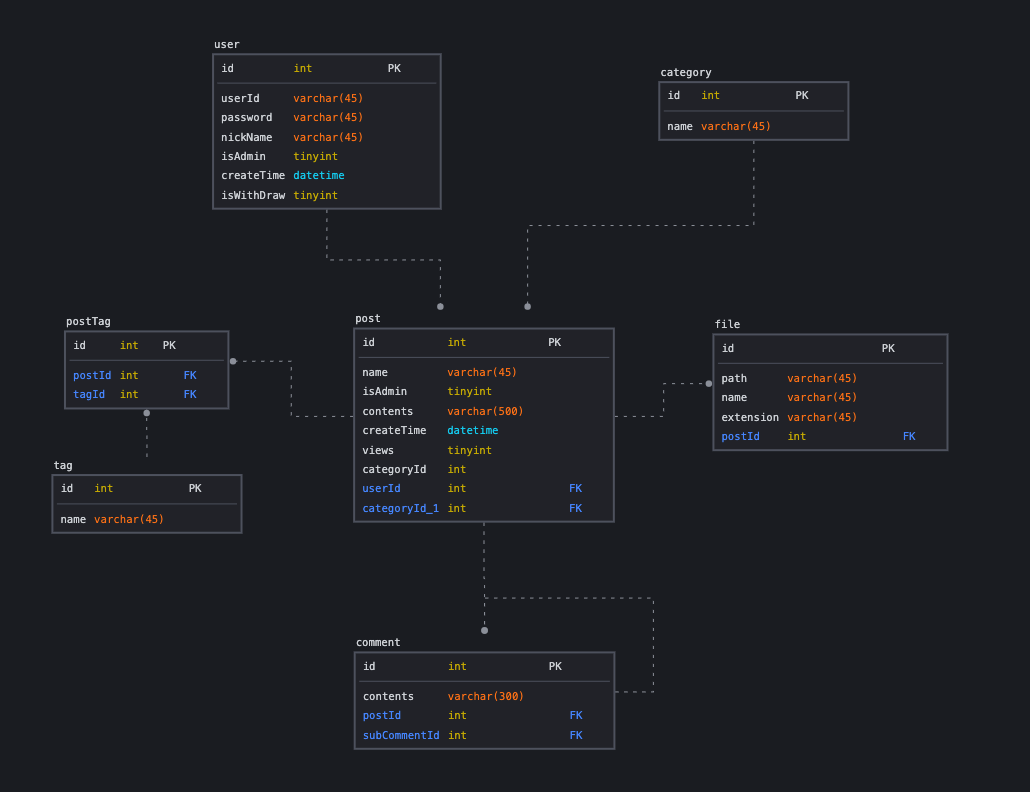
그리고 이 프로젝트의 ERD는 다음과 같다.
내가 만든 API 갯수로는 총 18개이고 각각 게시판 CRUD 4개, 그리고 카테고리 3개, 사용자 인증 관련 4개, 댓글 3개, 태그 2개, 게시물 검색 2개이다.
준비
먼저 테스트를 위해서 Locust를 이용할 것이다.
테스트를 위해 10만개의 게시물 데이터를 넣어보겠다.
from locust import HttpUser, task, between
import random
class AddPosts(HttpUser):
host = 'http://localhost:8080'
wait_time = between(1, 2)
def on_start(self):
self.client.post("/users/sign-in", json={"userId": "jybin96",
"password": "1213"})
@task
def add_post(self):
self.client.post("/posts", json={
"name": "테스트 게시글" + str(random.randint(1, 100000)),
"contents": "테스트 컨텐츠" + str(random.randint(1, 100000)),
"categoryId": random.randint(1, 10),
"fileId": random.randint(1, 10),
})
위 코드는 10만개의 데이터를 넣기 위한 Locust파일이고, on_start를 통해서 Spring 프로젝트의 로그인 관련 AOP를 위해서 설정해줬다. 테스트 실행시 add_post 함수가 실행되어 1초 ~ 2초 마다 게시물 생성 API에 요청을 보낼 것이다.
이 파일을 아래의 명령어를 통해서 실행시키고, localhost:8089 로 접속한다면.
locust -f 파일명.py

위와 같은 페이지가 나올 것이다. 여기서 사용자 수를 많이 입력한다면 그만큼 매초당 게시물을 생성할 것이다.
여기서 Spawn rate는 목표된 사용자 수를 얼마큼의 속도로 올릴건지 설정하는 것이다.
그 이후 쿼리를 통해 조회해보면서 원하는 수의 데이터를 만들어 내면 된다.

원본 테스트
자 이제 비교를 위한 게시물 검색 API 테스트를 진행해보자
나는 두가지의 시나리오를 구성했고 아래와 같다.
- 스트레스 테스트
- 500명의 동시 사용자
- spawn Rate 50
- 5분간 실행
- 스파이크 테스트
- 1000명의 동시 사용자
- spawn Rate 50
- 5분간 실해
이제 테스트를 위한 Locust 파일을 실행하고, 각각의 시나리오에 맞게 테스트를 진행해보겠다.
코드는 아래와 같고, 실행해주면 된다.
import json
from locust import HttpUser, task, between
import random
class BoardServer(HttpUser):
wait_time = between(1, 2)
def on_start(self):
self.client.post("/users/sign-in", json={"userId": "jybin96",
"password": "1213"})
@task(3)
def view_item(self):
sortStatus = random.choice(["CATEGORIES", "NEWEST", "OLDEST"])
categoryId = random.randint(1, 10)
name = '테스트 게시글'.join(str(random.randint(1, 10000)))
headers = {'Content-Type': 'application/json'}
data = {"sortStatus": sortStatus,
"categoryId": categoryId,
"name": name}
# print(data)
self.client.post("/search", json=data, headers=headers)
스트레스 테스트 결과


스파이크 테스트 결과


본론
이제 비교를 위한 테스트까지 마쳤고, Redis를 이용해서 캐싱처리를 해보고 비교 분석해볼 것이다.
준비된 프로젝트에서 Redis를 연동하고, 캐싱이 가능하도록 설정을 해보겠다.
먼저 의존성을 추가해준다.
// redis 적용
implementation group: 'org.springframework.boot', name: 'spring-boot-starter-data-redis', version: '3.1.0'
그리고 Redis 연동을 위한 Configuration 파일을 작성해준다.
package com.example.boardserver.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jdk8.Jdk8Module;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import java.time.Duration;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
@Value("${spring.data.redis.password}")
private String redisPassword;
@Value("${expire.defaultTime}")
private Long defaultTime;
@Bean
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
mapper.registerModule(new JavaTimeModule());
mapper.registerModule(new Jdk8Module());
return mapper;
}
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration();
redisStandaloneConfiguration.setPort(redisPort);
redisStandaloneConfiguration.setHostName(redisHost);
redisStandaloneConfiguration.setPassword(redisPassword);
LettuceConnectionFactory lettuceConnectionFactory = new LettuceConnectionFactory(redisStandaloneConfiguration);
return lettuceConnectionFactory;
}
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory, ObjectMapper objectMapper) {
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig() // 1
.disableCachingNullValues() // 2
.entryTtl(Duration.ofSeconds(defaultTime)) // 3
.serializeKeysWith(RedisSerializationContext
.SerializationPair
.fromSerializer(new StringRedisSerializer())).serializeValuesWith(RedisSerializationContext.SerializationPair // 4
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper))); // 5
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(configuration).build(); // 6
}
}
차례로 코드를 설명한다면 objectMapper bean은 직렬화에 대한 설정이다.
redisConnectionFactory bean은 spring 프로젝트와 redis의 연결에 대한 설정이다.
연결된 redis를 캐싱으로 이용하기위해서는 redisCacheManager라는 빈이 필요하다.
상세한 설명은 아래와 같다.
1. 기본적인 Redis 캐시 구성을 생성
2. null 값을 캐시하지 않도록 설정
3. 캐시된 항목의 만료 시간을 설정
4. 캐시 키를 직렬화할 때 사용할 Serializer를 지정한다. 여기서는 문자열로 된 키를 사용하기 때문에 StringRedisSerializer를 사용한다.
5. 캐시 값(객체)을 직렬화할 때 사용할 Serializer를 지정한다. 여기서는 Jackson 라이브러리를 사용하여 객체를 JSON으로 직렬화하는 GenericJackson2JsonRedisSerializer를 사용한다. ObjectMapper는 해당 Serializer에 필요한 설정을 제공한다.
6. Redis 캐시 매니저를 구성한다. RedisCacheManagerBuilder를 사용하여 RedisConnectionFactory를 제공하고, 앞서 구성한 configuration을 기본 캐시 설정으로 지정한다. 마지막으로 구성된 캐시 매니저를 반환한다.
이후 검색 API에서 캐싱을 적용해보겠다.
@Cacheable(value = "getPosts", key = "'getPosts' + #postSearchRequest.getName() + #postSearchRequest.getCategoryId()")
@Override
public List<PostDto> getPosts(PostSearchRequest postSearchRequest) {
List<PostDto> postDtoList = null;
try {
postDtoList = postSearchMapper.selectPosts(postSearchRequest);
} catch (RuntimeException e) {
log.error("selectPosts 메서드 실패", e.getMessage());
}
return postDtoList;
}
위 코드는 검색을 위한 Service단의 메서드이다.
캐싱 적용을 위해서 Cacheable이라는 어노테이션을 설정해주고 캐시의 이름을 사용하는 메서드 이름으로 설정하고 캐싱을 위한 식별자인 Key를 설정해주면 된다.
만약 다음 사용자가 같은 key에 대한 자료를 참조할때 캐시히트가 발생해서 메소드안의 로직을 타지않고 바로 Redis에 저장된 값을 반환하게 된다.
하지만 캐시 미스가 발생하게 된다면 Mysql DB에 접속해서 쿼리를 날려오고 그 값을 레디스에 저장하게 된다.
즉 처음 사용자가 게시물 검색을 하면 느리지만 캐시에 값이 저장하게 되고 다음 사용자는 그 값을 캐시에서 꺼내옴으로 속도가 아주 빨라지게 될것이다!
하지만 이렇게 되면 문제가 발생하게 된다.
만약 게시물을 작성한 사용자가 게시물 수정을 하게 된다면 캐시에 저장되어있는 값과 수정된 게시물의 값이 달라짐으로 무결성에 문제가 된다.
그래서 나는 어떠한 사용자가 게시물을 수정하게 된다면 캐시에 저장되어 있는 값을 삭제하도록 하였다.
@CacheEvict(value = "getProducts", allEntries = true)
@Override
public void register(String id, PostDto postDto) {
UserDto memberInfo = userProfileMapper.getUserProfile(id);
postDto.setUserId(memberInfo.getId());
postDto.setCreateTime(new Date());
if(memberInfo != null) {
postMapper.register(postDto);
Integer postId = postDto.getId();
if(postDto.getTagDtoList() != null) {
for(int i = 0; i < postDto.getTagDtoList().size(); i++) {
TagDto tagDto = postDto.getTagDtoList().get(i);
tagMapper.register(tagDto);
Integer tagId = tagDto.getId();
tagMapper.createPostTag(tagId, postId);
}
}
}
else {
log.error("register ERROR! {}", postDto);
throw new RuntimeException("register ERROR! 게시글 등록 메서드를 확인해주세요" + postDto);
}
}
CacheEvict 어노테이션을 이용해서 캐시 이름이 getProducts인 것을 삭제할 수 있다.
이렇게 코드를 작성하게 되면 Redis를 이용한 캐싱처리가 완료된다.
자 이제 비교를 위한 테스트를 진행해보자
스트레스 테스트


스파이크 테스트


결론
원본 테스트와 개선된 테스트를 비교해보면 확연한 차이가 돋보인다.
스트레스 테스트를 비교해보자면 원본 테스트는 초당 150건의 처리를 하고있고, 평균적 응답시간으로 2000ms가 걸리는 것을 확인할 수 있다.
Redis를 캐싱으로 이용하고 테스트를 진행한 결과는 초당 300건의 처리를 하고있고, 평균적 응답시간으로 8ms가 걸리는 것을 확인할 수 있다.
하지만 Redis를 캐싱으로 이용하는 방법을 무분별하게 모든 API에 적용하면 안된다.
그 이유를 찾아보니...
1. Redis는 메모리 기반의 데이터 저장소이므로, 저장된 데이터 양에 따라 메모리 사용량이 증가한다.
2. 수정이 일어나면 일관성 유지가 어렵다.
이 두가지가 가장 큰것같다.
즉 Redis를 캐싱으로 사용하기 위해서는 적절한 캐시 전략을 사용해야되고, 서버가 부담가능한 메모리를 생각해서 적절하게 사용해야 될것 같다!
'BackEnd' 카테고리의 다른 글
| Flask - 크롤링과 mongoDB 사용해보기! (0) | 2022.08.18 |
|---|---|
| Flask로 JWT 인증 방식으로 로그인 구현하기 (0) | 2022.08.16 |